Questo programma è stato progettato e realizzato per comprimere file utilizzando l'algoritmo di Huffman, tale algoritmo si basa sul contare i caratteri all'interno del file e successivamente assegnare loro una codifica più lunga se meno frequenti e più corta se più frequenti, in questo modo si potrebbe avere un guadagno rispetto alla usuale codifica in codice ASCII che assegna ad ogni carattere un intero byte.
Per realizzare un algoritmo del genere ho fatto uso delle varie classi presentate e descritte in questo fascicolo di documentazione, ma prima di procedere ad esaminare i metodi, vediamo le caratteristiche di questo programma.
Ecco una spiegazione delle scelte progettuali riguardo al Compressore:
Le fasi su cui si basa il compressore sono le seguenti: dato il file da comprimere, una prima operazione è il conteggio delle occorrenze di ciascun carattere (notare che ogni file può essere letto come sequenza di caratteri quindi questa operazione è efficace sempre) per fare ciò utilizzo un vettore di 256 interi dove memorizzo la frequenza di ciascun carattere se presente, 0 altrimenti, dopo di che provvedo a pulire il vettore allocando una struttura di tipo frequenza per ogni carattere con numero di occorrenze diverse da 0 (per fare ciò ho utilizzato una lista doppia in modo da non dover scorrere necessariamente due volte l'array di 256 interi, con puntatore ausiliario in modo da ridurre la complessità). Faccio comunque presente che questa operazione deve essere fatta sul file da comprimere in modo binario, infatti ogni carattere deve essere memorizzato in modo non formattato, una volta che ho allocato una struttura di tipo frequenza per ogni carattere presente posso aprire lo stream verso il file su cui scriverò la codifica, in esso verrà inoltre memorizzata una intestazione, come intestazione ho scelto di memorizzare prima di tutto il numero di caratteri diversi nel testo originale (in questo modo evito che il decompressore legga per due volte l'intestazione per costruire l'array delle frequenze senza sprecare spazio dato che se non mettessi questo carattere dovrei mettere un discriminatore alla fine dell'intestazione), per memorizzare il numero di caratteri diversi, dato che non possono in alcun modo superare i 256, utilizzo un carattere, infatti la codifica di esso va da 0 a 255, quindi mi basta memorizzare un carattere con codifica corrispondente al mio numero meno 1 (infatti se il file da comprimere è vuoto il file compresso non viene nemmeno creato); dopo il separatore verrà una serie di coppie carattere - frequenza, ognuna delle quali sarà separata dalla successiva da un separatore ('-') tranne l'ultima che potrà essere messa in contatto direttamente con il codice (notiamo che se evitassi di inserire il separatore allora un carattere numerico potrebbe essere scambiato come parte dell'intero che esplica la frequenza del carattere precedente e quindi avrei un grave errore). Questo metodo di memorizzazione dell'intestazione mi assicura che il decompressore sarà in grado di ricostruirsi l'albero di huffman a partire dall'intestazione, e notiamo inoltre che i caratteri non possono essere più di 256 quindi per l'intestazione esiste una dimensione massima (trascurabile rispetto a quella del file compresso su file iniziali sufficientemente grandi). A questo punto mi sono creato con la lista doppia un array di puntatori a oggetti di tipo frequenza allocati in memoria dinamica. questo viene passato al costruttore della classe heap che lo riorganizza costruendo un heap vero e proprio, il quale viene poi passato alla funzione huffman che mi costruisce l'albero memorizzandone il puntatore alla radice come membro dell'oggetto di tipo compressore, questo albero viene poi linearizzato tramite l'utilizzo della funzione linearizza, che semplicemente fa una visita dell'albero in modo ricorsivo andando a costruire un array di oggetti di tipo array di caratteri (stringhe del vecchio c, più efficienti degli oggetti string), questa operazione non è strettamente necessaria, ma viene svolta in vista di una più veloce compressione, infatti il tempo è molto maggiore se per ogni carattere bisogna esaminare da tutto l'albero. Una volta costruito l'array delle codifiche tramite la linearizza si procede con la traduzione e ad ogni carattere letto (in modo binario) si ricerca nell'array la codifica (notare che questa ricerca ha complessità O(1) perché l'array è stato creato in modo da potervi accedere direttamente conoscendo il carattere, questo è il metodo hash ad accesso diretto, dove ad un piccolo spreco di memoria corrisponde un notevole miglioramento di prestazioni) e si passa bit per bit alla funzione inserisci, metodo dell'oggetto di tipo IOs che viene usato per la scrittura della codifica, questa funzione provvederà a memorizzare i bit all'interno di un array di 8 booleiani per poi stamparli come carattere quando l'array fosse pieno o quando venisse invocata la funzione IOs::svuota(). Notare che per la classe compressore non è stato definito un distruttore, infatti il compito di deallocare la memoria dinamica allocata nelle varie fasi spetta direttamente al compressore, che cancella gli oggetti utilizzati appena risultano inutili.
Ecco una spiegazione delle scelte progettuali riguardo al Decompressore:
Per la decompressione ho pensato di utilizzare una classe di appoggio che ho chiamato IOl, la quale legge un carattere per volta memorizzando la sua codifica in un array di 8 booleiani e restituendo un bit alla volta per ogni chiamata della funzione IOl::leggi(), notiamo che il carattere viene acquisito (in modo binario) dal file compresso se e solo se il buffer è vuoto. Come per il compressore, anche il decompressore si basa su vari metodi che vengono invocati direttamente dal costruttore e anche questa classe non è dotata di distruttore in quanto gli oggetti inutili vengono cancellati appena possibile dal costruttore stesso. Come prima azione il decompressore definisce un oggetto di tipo IOl a cui passa il nome del file da decomprimere, un puntatore a oggetti di tipo puntatore a frequenza e un intero che vengono acquisiti come riferimenti, il decompressore apre quindi il file in lettura in modo binario e comincia a leggere l'intestazione, con i dati ricavati modifica l'intero e il puntatore passati, ora infatti il puntatore punterà ad un array di oggetti di tipo puntatori a frequenza già allocati, e l'intero sarà il numero di differenti caratteri presenti nel file originale. Facciamo notare che l'ultimo carattere che è stato compresso non necessariamente ha riempito il buffer della classe IOs, e quindi tramite la svuota() questa è stata obbligata a considerare i bit non presenti come 0 e memorizzare comunque nel file il buffer come carattere, tuttavia questi 0 presenti in coda potrebbero essere erroneamente interpretati dal decompressore come caratteri codificati, questo significa che devo trovare un modo per evitare che quegli ultimi caratteri vengano tradotti. per far ciò definisco un vettore di 256 interi tutti inizializzati a 0: ogni volta che verrà tradotto un carattere incrementerò la cella corrispondente alla sua codifica di una unità e quando verrà tradotto l'ultimo byte, se l'intero nella cella di occorrenze[] superasse la frequenza del carattere presente nell'intestazione, interrompo la scrittura ed esco normalmente, tuttavia se questa stessa cosa dovesse succedere prima dell'ultimo byte allora sarebbe errore e quindi viene lanciata l'eccezione. Dopo aver costruito grazie alla classe IOl l'array delle frequenze, questo viene passato al costruttore di un oggetto di tipo heap (che implicitamente lo riorganizza come heap), questo oggetto di tipo heap viene poi passata alla funzione huffman metodo del decompressore in tutto e per tutto identica a quella nella classe compressore, questa funzione provvede a costruire l'albero di huffman il quale indirizzo della radice viene memorizzato all'interno di un puntatore. Dato il fatto che la funzione IOl::leggi() restituisce -1 se e solo se il file è terminato allora devo tenere memoria all'interno del decompressore dell'ultimo byte acquisito, infatti se ogni volta stampassi e leggessi non sarebbe in alcun modo possibile stampare correttamente l'ultimo carattere, quindi fornirò la classe decompressore di un buffer che terrà in memoria l'ultimo carattere letto e che verrà tradotto sul file decompresso se e solo se la lettura del byte successivo è andata a buon fine. Quindi dopo una prima lettura del buffer viene invocata la funzione traduci che provvede a stampare il contenuto del buffer interpretandoli in base alle codifiche, infatti utilizzerò un puntatore che a seconda del bit mi scorrerà sull'albero di huffman e quando arriverà ad una foglia verrà stampato il carattere corrispondente e verrà incrementata la cella corrispondente nell'array occorrenze[]. Quando la IOl::leggi() ritornerà il valore -1 vorrà dire che il file compresso è terminato ma grazie al buffer di decompressore avrò ancora l'ultimo byte letto, che verrà decompresso normalmente fino alla fine o fino a che l'intero in occorrenze[] non sorpasserà la frequenza registrata nell'intestazione.
Nel file main di questo programma è inoltre stata inserita una gestione delle eccezioni: esse vengono generate in profondità dai vari metodi delle classi utilizzate, ma vengono catturate a livello più alto, dal main, in modo che si possa attuare un migliore trattamento senza bisogno di bloccare il programma
Una spiegazione del funzionamento di ogni funzione è presente nelle altre pagine di questa documentazione e ad ogni funzione è stata associata la relativa complessità. Facciamo però notare che per questo problema è difficile dare uno studio di complessità accurato perché abbiamo più dimensioni disponibili... nelle pagine di documentazione per il progetto indicherò con n il numero di caratteri diversi nel file e con m il numero di caratteri effettivi nel file da comprimere. Notare inoltre che tali misure sono solo indicative in quanto per ricavarle ho eseguito alcune approssimazioni, comunque danno un' idea del costo di esecuzione di una compressione o di una decompressione. Si ha inoltre l'effetto che n potrà essere al massimo 256 e quindi ha un limite superiore, questo parametro potrebbe essere trascurato per la valutazione delle prestazioni, ma io preferisco inserirlo perché quando i file sono molto piccoli e i caratteri vari questo fattore assume grande importanza.
Per dare una idea della potenza di compressione, innanzitutto notiamo che la compressione è minore se vi sono più caratteri diversi nel testo specialmente se essi hanno frequenza molto simile, mentre è massima se i caratteri sono spesso ripetuti e se hanno frequenza molto diversa, questi parametri influenzano grandemente la compressione, infatti per darne una idea ho riportato in questa pagina due grafici molto significativi:
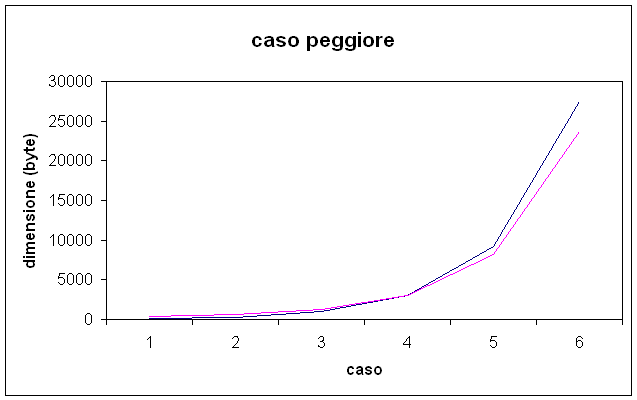
CASO 1
Ho scritto 6 file dove ho memorizzato tutti i caratteri scrivibili direttamente da tastiera, in ogni file ripetuti per un numero crescente di volte, nel seguente grafico si da una idea del fattore di compressione, esprimibile come la differenza tra la dimensione del file originale e quella del file compresso, notare che questo è un caso pessimo, ma non è il peggiore, infatti in un file vi potrebbero essere tutte le 256 combinazioni concesse dal codice ASCII (8 bit) tutte con la stessa frequenza, e in quel caso potrebbe rivelarsi sconveniente comprimere, specie per dimensione piccola
Dove la linea blu scuro è il file originale e quella viola chiaro è invece il file compresso, come si può notare, all'inizio addirittura il file compresso supera in dimensione quello originale, questo è dovuto alla intestazione che occupa spazio per permettere al decompressore di leggere la codifica. Tuttavia quando la dimensione aumenta il fattore di compressione comincia ad essere positivo e cresce al crescere della compressione.
CASO 2
In questo caso ho scritto 6 file e in ognuno ho memorizzato un singolo carattere ripetuto in numero crescente di volte fino ad arrivare a 30000 volte per il caso 6, mi aspetto che in questo caso il fattore di compressione sia massimo e infatti i grafici sono
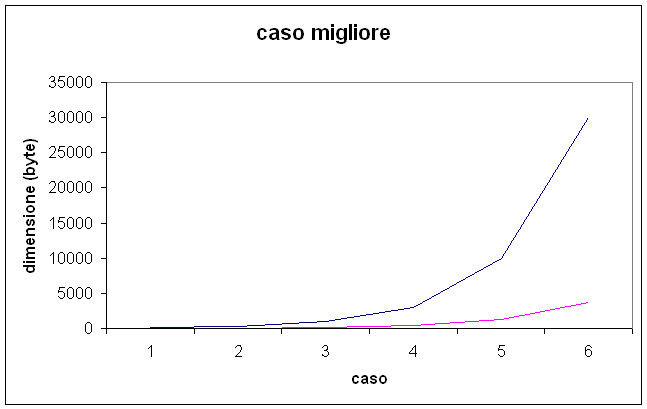
Come si vede in questo caso, la dimensione del file compresso è minore di quella del file originale già a partire dal primo caso, questo significa che in questo caso è estremamente conveniente comprimere, al caso 6 il fattore di compressione è molto alto, infatti mentre il file iniziale è di 30000 byte quello compresso è esattamente di 3758 quindi il fattore di compressione è addirittura 26242 bytes.
Per valutare il programma prendendo come misura il tempo questi piccoli file risultano inutili, riporto quindi a seguire un solo grafico con sull'asse delle y il tempo e sull'asse delle x la dimensione del file, dove il file più piccolo considerato è in questo caso da 1 MB
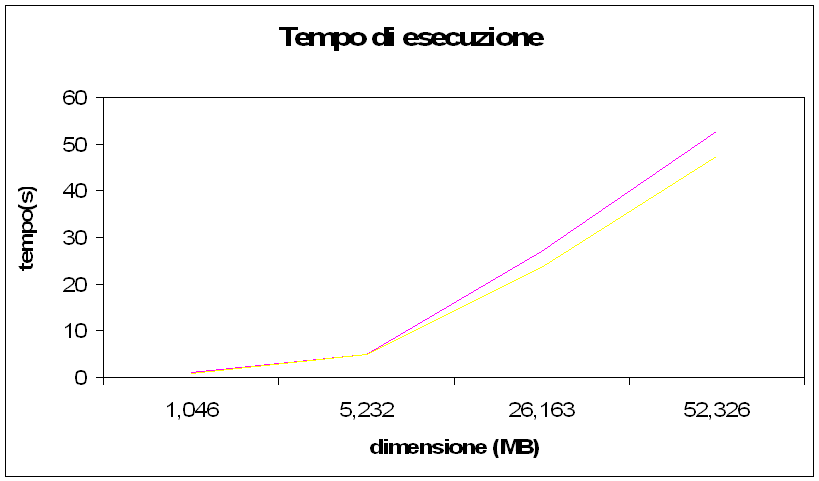
Nel grafico sono presenti due linee una di colore giallo per il tempo computazionale impiegato dal decompressore e quella in rosso che rappresenta il tempo computazionale impiegato dal compressore. Per costruire questo grafico ho esaminato solamente 4 casi, di dimensione pari ai valori sull'asse x, come si vede l'andamento della complessità dell'algoritmo è molto vicino alla linearità (il grafico è molto simile ad una spezzata per la povertà dei dati, tuttavia si capisce che l'algoritmo ha una complessità lineare nel numero di caratteri presenti nel file. questa conclusione a cui siamo arrivati ad intuito viene confermata nell'analisi della complessità di ogni funzione presente nella documentazione a seguire che ci svela che il compressore ha una complessità pari a O(m) dove m è il numero di caratteri nel file, tuttavia notiamo che il decompressore ha una complessità pari a m * log n. Questa differenza non è tuttavia apprezzabile in file così piccoli dove la maggior parte del tempo va alla lettura e alla scrittura dei caratteri da/su disco
Fatte queste considerazioni si può procedere ad analizzare gli oggetti di questo programma